Tech
Internet Basics #3: HTTP requests explained


HTTP works via the client–server model: the client sends a request to the server and based on that request, the server sends a particular response back to the client. This request can be anything from retrieving a web page to creating a user account from a given username and password. Individual requests are independent from each other: for a single request, a single response is sent back.
Apart from HTTP, we often see the HTTPS protocol in web addresses. This stands for Hypertext Transfer Protocol Secure and indicates that the communication has an extra layer of security, so malicious actors can’t easily interrupt it. In a previous post about SSL, we’ve explained what exactly this means and how it works. It’s important to note that everything we discuss in this article applies to HTTPS as well.
HTTP requests can be used for many different purposes, each of which is indicated with its own so-called “method.” Only a select few of these methods are frequently used and are important to know. The most prevalent method is the one you’ve used to get to this very blog: the GET method. This method, as the name suggests, is used for retrieving information from the server. One of these was sent by your browser when you clicked on a link to read this article in order to retrieve the HTML of this web page.
If, for example, you want to send information to a web server to log into an account or to fill in a form, the POST method is used. Two other often used methods are PUT and DELETE. PUT is very similar to POST but is used to update existing records rather than create new ones, and DELETE, as you might have guessed already, is used to request the deletion of certain data.
But how exactly are these methods used when sending a request?

Figure 1 gives a visual representation of an HTTP request. At first, this might look daunting, but we’ll break it down and look at the individual parts. This is a request to a server which processes the text we give it and, in this case, gives us back an HTML page with our text in a heading. The first part of the request we send to this server is the request line, which is made up of three components: the method, the target and the protocol version. This line tells the server what action we want to take, in which destination that action should be taken and – to avoid confusion – what exact protocol we want to use to communicate. In our case, this is a GET request because we want to retrieve an HTML page. We’re sending this request to the (fictitious) /test endpoint using the HTTP version 1.1 protocol.
Next up are the headers. Request headers can be seen as metadata which informs the server about the data that is requested and about the client sending the request. These headers can be further divided into categories, but we’ll ignore them for now. In our request, we need to pass several headers to tell the server what our request looks like – through the Content headers – and what we expect in return from the response – through the Accept headers. The host header ensures the request is sent to the correct server.
The User-Agent header tells the server what device we’re on and what browser we use. This header looks different for each device type but commonly starts with Mozilla/5.0 to indicate that the browser is compatible with Mozilla. This is only a small selection of possible headers that can be passed with a request. For a complete overview, check out the Mozilla documentation on HTTP headers.
Finally, separated from the headers with a single empty line, is the request body. This is optional as not every request requires content to be sent to the server, but in our case we want to send some text that will be presented in a heading. This is a very simple example and the request body can be much more complex with even multiple resources.
After processing the request, the server will return a response. If the request is successful, the response might look like this:
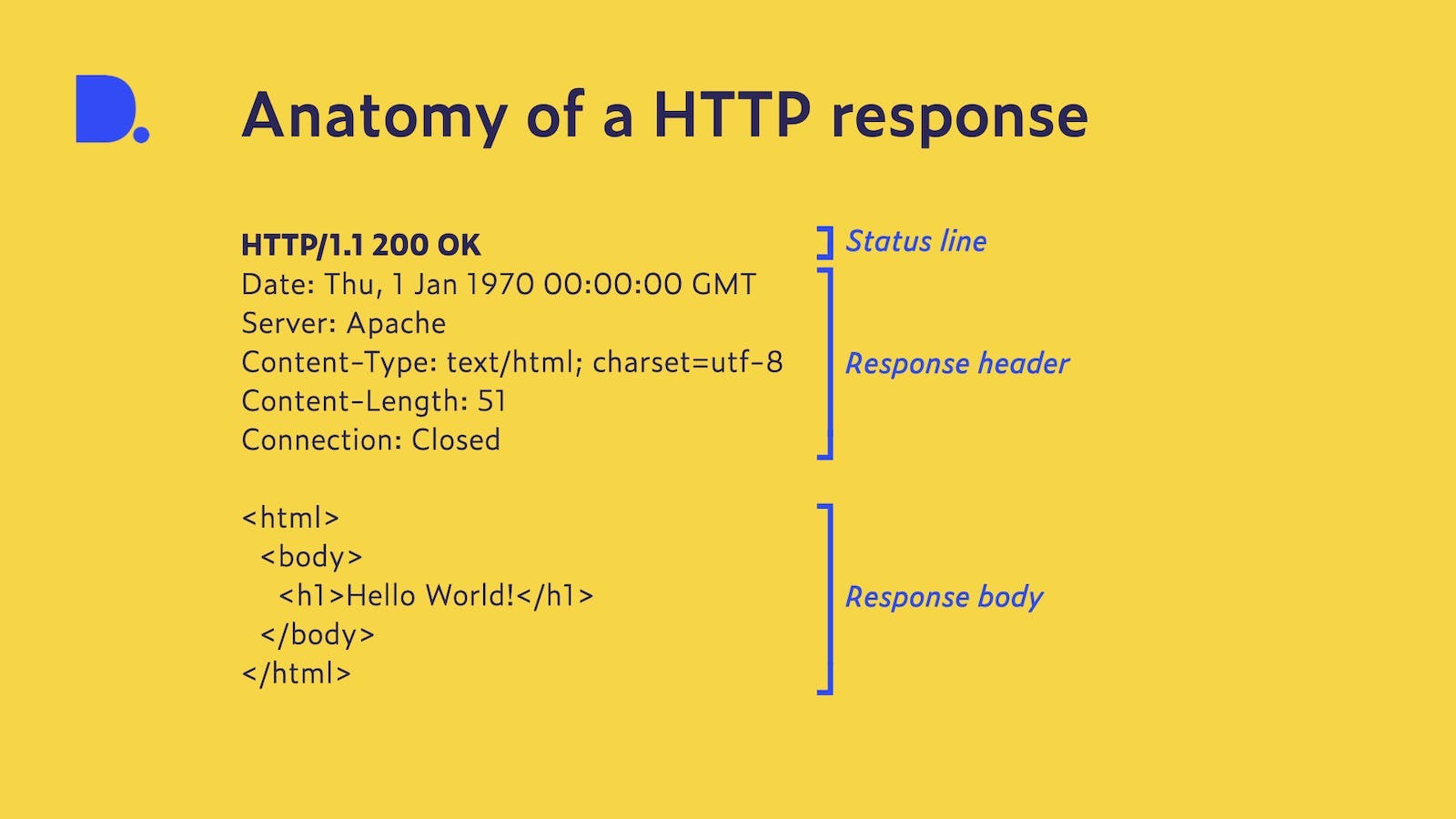
The HTTP response is structured very similarly to a request. It starts with a status line that lets the client know which HTTP version is used and how the request has been handled through a status code and a complementing status message. These status codes are divided into five categories and indicate the success or failure of the request. Since our request was successful, we got the status code 200 with the text ‘OK’, indicating that everything has gone as planned. This and other status codes can be found in our proprietary data in which we save the response code and headers of every website we crawl.
The status line is followed by the response headers that provide information about the server and the returned content. This content is once again separated from the headers with an empty line and, in our case, contains the HTML structure for a web page with the text we’ve sent to the server in a heading.
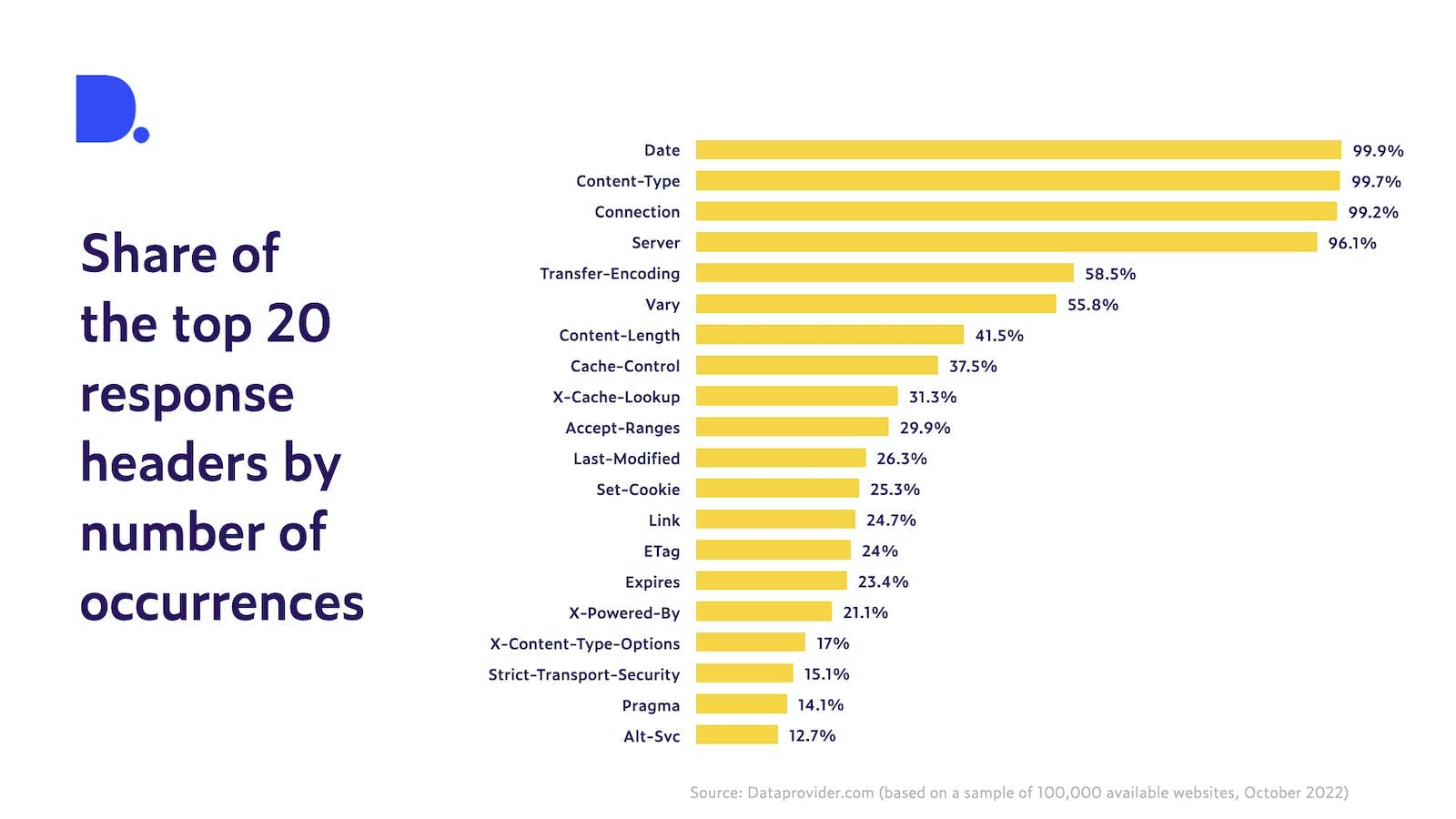
Figure 3 shows the 20 most occurring response headers from a large sample of available websites from our proprietary data. We can see that some headers occur in almost every response. This makes sense as they contain some very generic information which most responses need, such as the timestamp of when the response was sent, the type of content it sends back or if the connection to the server will be closed or not.
Hopefully, now you know a bit more about the complex nature of the internet and what goes on behind the scenes when you visit your aunt’s blog or update your LinkedIn profile.

