Tech
Data quality: a glimpse into our annotation team

For an algorithm to learn what information is important and how to allocate a website to a certain category, we first need to train the algorithm with a list of websites that are already correctly classified. In order to create those lists, we employ several people whose task is to scan through thousands of websites each year to help train our classifiers.
This is very important work as it helps us to ensure and continuously evaluate data quality. There are different types of annotations the team makes, sometimes it is a yes or no decision, for example if a website is an online store. Other types of annotations are more elaborate, for example, determining the name of a company and extracting address information. In the video below you can see how our annotators go through different websites to extract information and record information on whether the site is an online store. To facilitate this process, we developed a custom tool that aids in the recording of information.
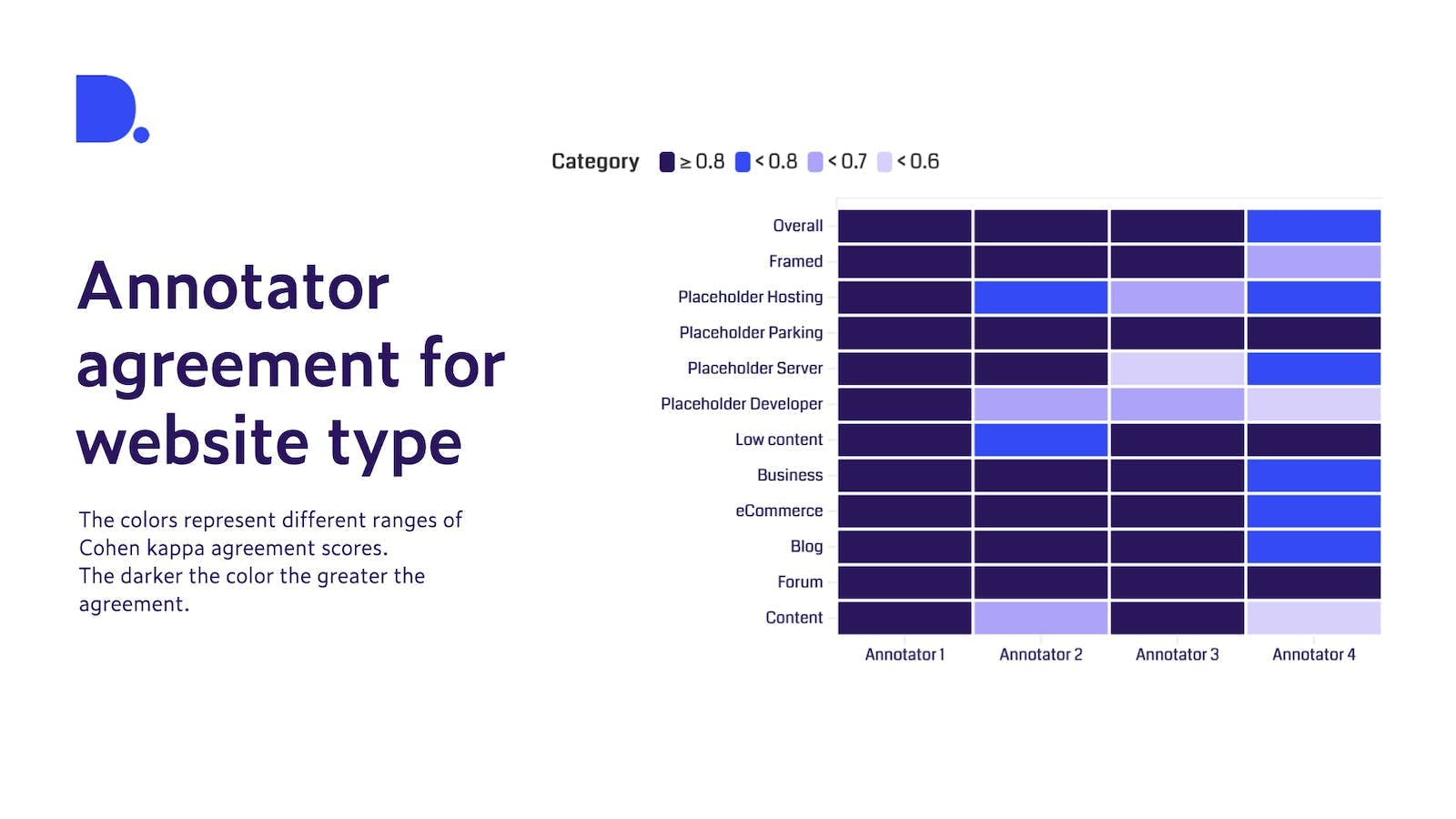
When we build a new classifier we start off with a relatively short list of websites for each annotator. Then we determine how much the annotators agree with each other. This is done by our data analytics team that calculates an agreement score, called Cohen’s kappa coefficient to measure inter-rater reliability. In Figure 1 below you can see how well annotators agree on website classification. Overall annotators 1-3 are performing similarly, annotator 4 might find this task a bit more tricky. For some websites it is relatively easy to determine the type, such as a forum and what is called a placeholder-parking. But for other types of placeholders (e.g., hosting and developer), nearly all annotators show some level of uncertainty. In such cases we first discuss the reasons within the team for any uncertainties, then review our definitions and concepts and repeat the process until we reach a high level of agreement.
Once the team reaches a high level of agreement, we move on to the next round of annotations. Usually, during this second stage an annotator goes through a longer list of randomly selected websites. We sample those on the same day as our spider crawls the web so we ensure information used for existing classifications and the one our annotators see is the same. Each annotator also regularly goes over the lists their peers have already annotated to ensure continued agreement and detect any mistakes that may have occurred.
One frequent challenge our data analytics team faces is to determine just how many websites need to be annotated to ensure the classifier is trained well but at the same time keep the number of annotations as low as possible to reduce workload.
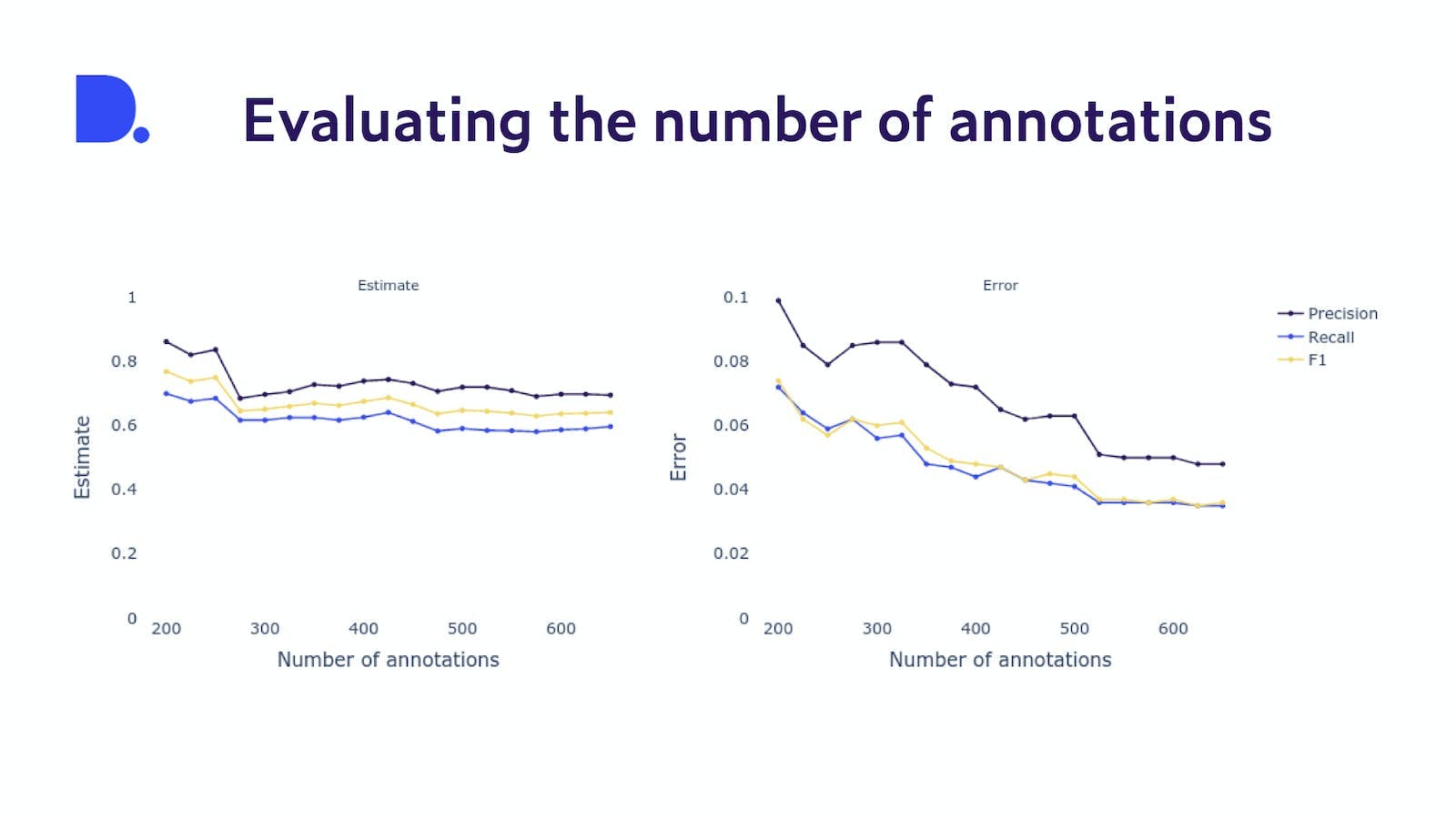
We calculate various metrics to achieve exactly that. In Figure 2 you can see the evaluation (F1, Precision, Recall) of the detection of a field and its error versus the number of annotations. With bootstrapping we can calculate the estimate metric (graph on the left) and the error of this estimate (graph on the right). We can see that after approx. 500 annotations, the estimates are stabilising while the error maintains over 0.05. We stop annotating at 650 annotations because the error is finally below 0.05.
As you can see, annotating websites is a challenging and time-consuming process but is absolutely crucial when it comes to structuring data, to ensure our data is accurate and adheres to the highest quality standards. Last year our annotators visited tens of thousands of websites, delivering data for classifiers, data surveys and field quality evaluations. They are one of the few people in the world that have been to the strangest and weirdest corners of the web. If they find a hidden gem they’ll share it with the rest of the company and because this has been a lot of fun, we'll soon be sharing some with you in our upcoming LinkedIn posts.


