Tech
Internet Basics #4: The difference between crawling and scraping


In our Internet Basics series, we discuss the fundamentals of the internet. Today we'll look into the differences between crawling and scraping and explain how we bring structure to the information chaos that is the World Wide Web.
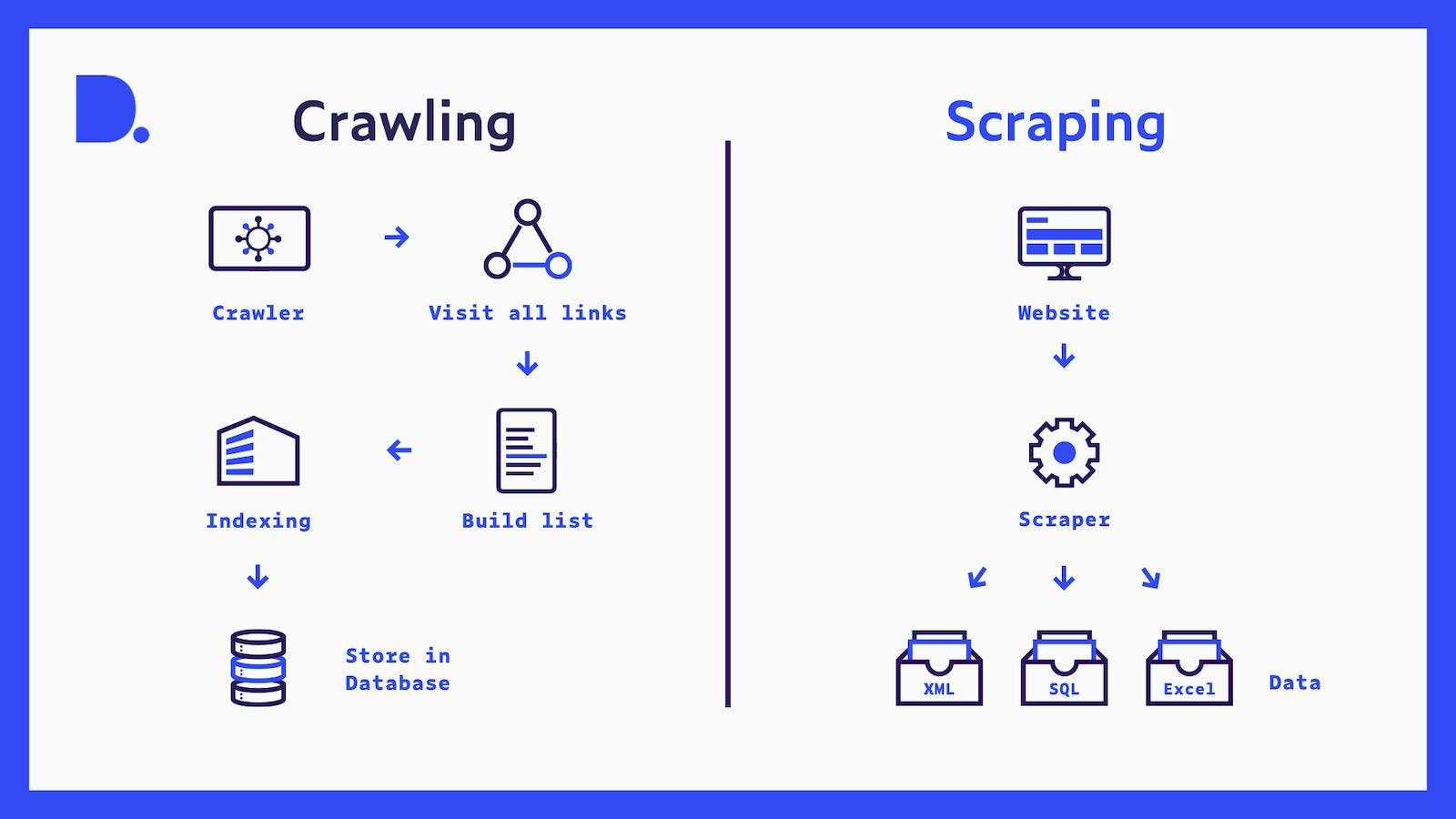
Each month, Dataprovider.com indexes over 750 million domains in over 50 countries. Indexing refers to the process of collecting, parsing and storing data to enable fast information retrieval. To index the web, we first need to discover and visit the web pages from which we can extract our data. This discovery process is called crawling. A crawler (sometimes also called spider or robot) is a software application that automatically visits websites and finds new websites to explore. In most cases, crawlers are operated by search engines.
A good analogy for a crawler would be a librarian going through a large unorganized pile of books.
A good analogy for a crawler would be a librarian going through a large unorganized pile of books. The librarian reads a few pages from each book and the title to put it in the correct category so that library visitors can quickly find the information they need. However, in the case of the crawler, we can’t know exactly how many web pages we need to browse. Crawlers, therefore, apply a different process.
What a Crawler does
To discover websites, a crawler does the following: First of all, the crawler starts from an initial list of hyperlinks. The crawler program visits a web page from the list and identifies all hyperlinks on it. The newly discovered hyperlinks are then added to the list and are handled by repeating the previous step.
The process of extracting content from a web page is called scraping.
Due to the massive size of the internet, crawling is a large-scale operation that requires a huge amount of computing power. As it’s impossible for a crawler to visit every URL on the world wide web, it needs some type of measure to select the most important pages. Often, the number of referrals to a specific website defines its importance.
If you’re interested in building your own crawler, you don’t have to start from scratch: you can use popular open source web crawler systems such as Pyspider, Apache Nutch or Heritrix by the Internet Archive. These programs are built with scalability in mind and offer integrations with popular databases such as MySQL, MongoDB and Redis.
What is Scraping?
The process of extracting content from a web page is called scraping. Often, scraping is tailored to extracting information from a specific website or group of websites. For example, a scraper could be explicitly designed to obtain product prices from Amazon for a price comparison website. Other usage examples are automatically retrieving real estate listings for a real estate platform or tracking online presence and reputation for marketing purposes.
As most web pages are designed for humans, and not for automatic processing, it can be difficult to gather the required information from the web page. Modern websites typically use JavaScript frameworks to create a smooth and interactive user experience. As JavaScript is executed in the user’s browser, the effects of these scripts can’t be captured if a scraper is just looking at the HTML code of a website. Moreover, scrapers are highly sensitive to (changes in) the web page layout. Scraping systems, therefore, frequently have specific features to deal with these difficulties. For example, features to allow full JavaScript execution or features to handle pagination and infinitely scrolling web pages.
In most cases, website owners don’t want their content to be scraped since it isn’t beneficial to them. Scraping brings additional traffic, which slows down website load times. More importantly, most website owners don't want their information to be copied and used beyond their control. Frequently scraped targets may therefore actively repel scrapers by taking measures such as rate limiting, detecting unusual traffic and obfuscating website code. As a consequence, scrapers often try to mimic human users to remain anonymous. This is accomplished through actions such as simulating how a human user would see and browse a webpage, faking user agents (pretending to be a regular web browser) and using residential IPs.
In comparison, most crawlers adhere to legal standards and introduce themselves using the User-Agent HTTP request header when visiting a website. For example, the User-Agent is set to “Googlebot” for Google’s crawler, and “Bingbot” for Microsoft Bing’s crawler. Crawlers only index publicly accessible information. If website owners don't want their websites to be (fully) indexed, they can include a robots.txt file in the main directory of their website. This allows them to explicitly specify which parts of the website a crawler may or may not index.
Alternatively, the indexing of a webpage can be blocked by including the noindex meta tag in the website code. Besides this, many crawlers have a crawl budget, which means they only visit a specified number of URLs from an individual domain in order not to put a burden on the website. Most crawlers visit a website only from time to time to check for updates, while scrapers visit more frequently.


